In this post, I collate, re-organize, and summarize literature relevant to computational advertising today, with the objective of being able to structure problems that warrant data-driven solutions: either in the form of mathematical models, software systems, or business and creative processes.
The article is organized as follows:
First, for the uninitiated, I provide a brief background of this extremely dynamic area of computational advertising.
Next, I describe what is popularly known as the computational advertising “landscape” that constitutes various stakeholders.
Lastly, I take up each stake holder and bring out the importance of using data to potentially improve their returns.
If you’d like to skip the introduction and head directly to the data science section, click here.
Much of the introductory content in this post has been based off of the references [1] and [2], tossed and baked, and a pinch of seasoning added, to make it relevant for the discussion-at-hand.
Introduction to computational advertising: History and Definition
Advertising is a marketing message that attracts potential customers to purchase a product or to subscribe to a service. [1]
Apparently, advertising is a rather old phenomenon.
The Ancient Egyptians carved public notices as early as 2000 BC. In 1472, the first print ad was created in England to market a prayer book. Product Branding came into being with the copy developed for Detrifice Tooth Gel in 1661. The birth of the billboard gave raise to the billboard in 1835, and the first electric sign was up in Times Square in 1882. Radio advertising began in the 1920s and the first TV commercial ran in 1941. [2]
Internet advertising, however, is just about a decade old and yet has become a pervasive phenomenon that has lead to the creation and growth of several Internet giants.
Search advertising started through Goto.com in 1998; Goto.com became Overture, was subsequently acquired by Yahoo! in 2003, and re-christened Yahoo! Search Marketing. Meanwhile, Google started Adwords in 2002 that incorporated bidding for keywords for displaying advertisements in search results. Since then, we have seen the emergence of the “Big 5” players, namely, Facebook, Google, Twitter, AOL, and Yahoo!
Off late, the aforementioned large organizations are also consolidating with other players to extend the range of services offered and the ability to capture the most “user activity” and “facetime” on the Internet. Some of them include the acquisition of Atlas by Facebook; DoubleClick, Oingo, and Dart by Google; Bizo with LinkedIn; Marketo with AOL; MoPub with Twitter, and Advertising.com Sponsored Listings by Microsoft.
Dempster and Lee [2] interestingly describe the current state of the advertising industry as the age of the customer, in contrast to the age of the brand of the 1950s when brands like Tide and Chevrolet became household names owing to their ad campaigns through TVs and mailers. The age of the customer, they describe is characterized by companies like Capital One and GEICO that use individual-level data and analytics to target and personalize direct marketing efforts that lead to large scale customer acquisition and relationship building. This advancement owes to the advent and popularity of technology that can operate at scale; the growth of digital media, proliferation and penetration of social media, and the large growth of a multi-screen always-on-mobile population.
From hereon, this paradigm of advertising of the “age of the customer” that uses the internet, WWW, smart-phones, and the like along with computational infrastructure that can perform computations and in a principled way to match advertisers to customers shall be called Internet Advertising, Online Advertising, or Computational Advertising, interchangeably.
The Advertising Landscape
The stakeholders
The various stakeholders of the computational advertising landscape is given below. It has been derived from [1] and [2].
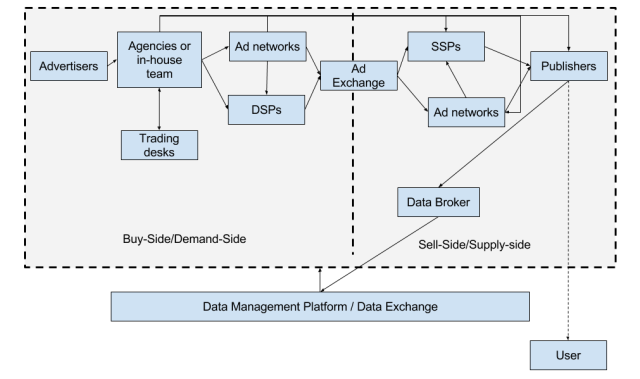
Advertisers are the folks who want to advertise their products and services.
Advertisers intend to “convert” people from a state of disinterestedness to a loyal customers who continually use the advertiser’s product or service. This is commonly abstracted as a marketing funnel given below.
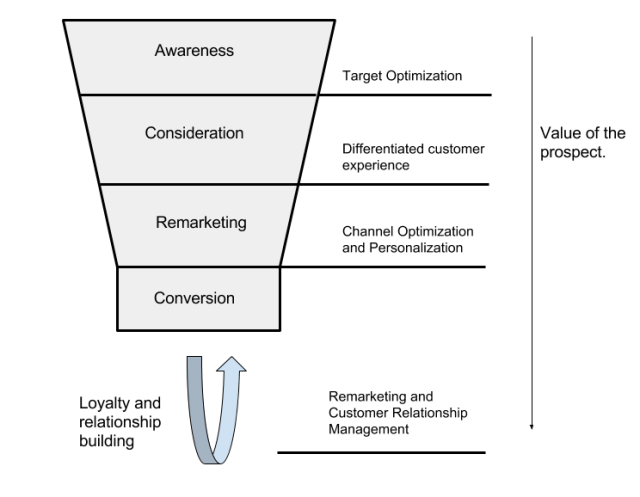
The top of the funnel comprises of prospects that are large in number and are selected based on customer segmentation and audience creation. Traditionally, this segment was addressed between the 1950s and the 90s through mass media like Television and Radio, and through mass mailers. As a prospect moves down the funnel, the possibility of a “conversion” is enhanced by personalizing the experience for the customer either online or offline, so that his/her specific needs are addressed. Lastly, a “converted” prospect who becomes a customer is a potential candidate for cross-selling offerings. Also, building a good relationship with him/her develops loyalty and helps business grow and sustain. E.g. Chevrolet, IPL, Tata, NFL, Nike
Agencies are companies that manage the spend of marketing money by designing, executing, and monitoring the ad-delivery experience for the advertiser. The agencies have to work in tight co-ordination with various stakeholders in the organization; sometimes, an in-house team performs the work of the agency as well.
With the sudden advent and necessity of using many technology “pieces” in delivering advertisements today, it has become a challenge for traditional ad-folks to keep pace and be relevant. As a result, holding companies of agencies have come up with the concept of trading desks that have the necessary skill sets siloed up in a separate organization that demands usage fee for its services. E.g. Havas Media, Omicom Group, WPP Group
Ad Networks are companies that specialize in matching advertisers to publishers. They operate on the model of arbitrage – by making the money that amounts to the difference of the publisher’s earnings and what the advertiser is willing to pay. These companies predate ad exchanges that are explained below. Ad networks traditionally suffered a lack of transparency, and sometimes, had unsold inventory that were sold to other ad-networks, leading to many “hops” for an advertiser to sometimes find inventory (known as daisy-chaining), leading to very high arbitrage. Such limitations of Ad Networks gave way to today’s Ad Exchanges, DSPs, DMPs, and SSPs. E.g. Tribal Fusion, Specific Media, Media.net, Conversant.
Ad Exchanges are companies that provide the necessary infrastructure for the publishers to sell their inventory through a bidding process to the advertisers. Since the market is fragmented with many ad-networks, publishers, and advertisers, publishers and advertisers often don’t directly connect to the ad-exchange and instead go through other companies called DSPs and SSPs, respectively. Today, most Ad Exchanges use a standard called OpenRTB [35] for their services. E.g. Google Ad Exchange, Yahoo! Ad Platform, Microsoft Advertising Exchange, MoPub, Nexage, Smaato
Demand-side Platforms (DSPs) serve the agencies (and hence the advertisers) by bidding for inventory. Their objective is to provide maximum return on the ad spend (ROAS) for the advertisers. They may do so by connecting to multiple Ad exchanges, networks, and SSPs. E.g. DataXu, MediaMath, Turn, Adnear
Supply-side Platforms (SSPs) serve the interests of the publishers by connecting them to various ad-exchanges and networks to sell their inventory for the best price. E.g. Pubmatic and Rubicom
Data Management Platforms (DMPs) enable publishers and advertisers to store their data in a centralized system and re-use it for optimizing their actions (e.g bidding) or assets (e.g inventory placement). DMPs, as platforms are diverse and sometimes also enable storage of data (owned, derived, and bought) in a form that can be used for analyses, segmentation, and optimization. Also, they may act as a market place or a syndicate for various stakeholders to purchase, combine, and triangulate data. Generally, DMPs are of three kinds:
- Execution DMPs: that are geared towards certain types of channel and media with core DMP functions for use by DSPs.
- Pure-play DMPs: are the most common type in the market that in addition to performing core DMP functions of managing data, provide a rich interface to connect to various channels and media, syndicate various data sources, and also possibly a “data exchange” capability to purchase, sell, and integrate third-party data.
- Experience DMPs: that go beyond basic DMP functionality and provide tight integration with work-flows for personalization and “experience” management. By experience, we refer to the experience that a prospect would go through, as he/she moves through the conversion funnel.
Publishers are social media sites, websites, apps, televisions, radios, and other platforms that display advertisements to a prospect. The prospect is called the user of the publisher’s services in the block diagram given above.
Lastly, it is to be noted that the publisher is also sometimes known as the seller and the advertiser is known as the buyer (of ad slots). Therefore the companies that represent the interests of the advertiser are on the supply-side or sellers’ side of the platform and those representing the interests of the advertisers are known to be on the demand-side or the buyers’ side of the platform.
A detailed list of companies falling of the advertising landscape is given in LUMAScape [3].
Technology abstractions
A modified version of various technology abstractions that have to be implemented, customized, or re-used for implementing a computational advertising solution from Dempster and Lee [2], is given below.
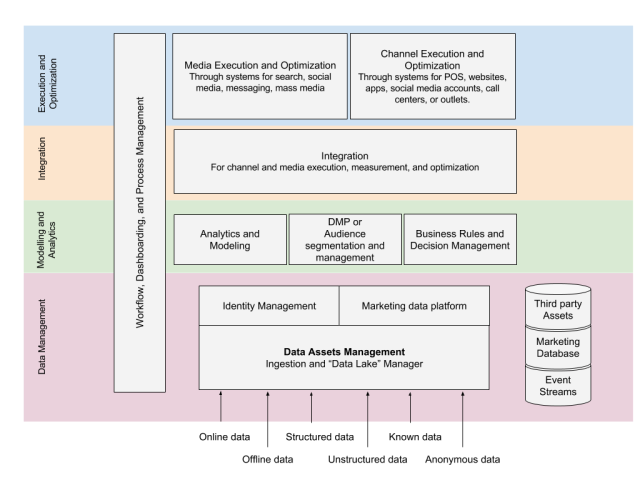
Data Assets Management refers to the ingestion and house keeping of various kinds of data available to the advertiser from third-party sources and owned assets. The data could be structured (questionnaires, relational tables from signup forms etc.) or unstructured (forum posts, contextual information from user pages, etc.), attributable to an individual user (aka known data) or anonymized. Since the data collected at this step is heterogeneous, it could be abstracted as a “data lake” that is a central, comprehensive repository of all information. This information can be re-organized and normalized into traditional relation tables or other storage forms that assists with other functions such as analytics, decision making, and optimization. This can be called the Marketing data platform The data assets management layer is also used to manage Identities: i.e. associations of interactions at touch-points and behavioral data with unique identifiers, so that individual users or “look-alikes” can be identified and handled appropriately. Lastly, an important kind of data that has to be stored are event streams which are raw captures of interactions at touch-points for every user. This is closely related to identity management and can be used to solve interesting problems like “attribution” which is discussed later in the article.
The data that has been ingested by the aforementioned Data Management layer is used for three purposes: for analysis and understanding, modeling and segmentation, and optimization.
Analysis could help understand the quantity and quality of data stored, performance of ad campaigns, and ad operations. Modeling refers extracting derived features, fixing missing data, and creating audience segments or groups that can be used for targeting. Lastly, optimization involves building business rules for creating a user experience, developing creatives, and coming up with strategies for spending money. While fine-grained experimentation, measurement, and optimization will have to happen while working with various media sources and channels, an overall strategy and decision making matrix is nevertheless necessary. All these three functions are shown in the Analytics and Modeling layer of the diagram.
Next, all the block diagrams discussed so far are usually developed by separate teams or are be based off of existing products. Their integration with other components for media and channel optimization such as DSPs, AdExchanges, web analytics providers, event stream trackers, etc. is therefore a distinct and important task and is referred to as Integration.
Lastly, we have two blocks that deal with media and channels, respectively.
The media execution and optimization block deals with various systems such as API driven Ad Networks, Ad Exchanges, Publisher APIs, and DMPs and algorithms for various tasks like price estimation, burn-rate estimation, and bidding decision making for RTB, and the like.
The channel execution and optimization block deals with various channels through which the advertiser wishes to engage with the prospect. They could be landing pages on a website, an app, a brick-and-mortar store, or a call center. The “experience” of a prospect as he goes down the conversion funnel has to be personalized and optimized to drive a conversion. This uses the outcome of the “creative” work of developing content and various techniques to “personalize” the experience of the user by exposing them to the right content and guiding them down the funnel.
Each abstraction discussed above is also closely tied to business processes, work flows, and manual interventions. All of this has to be managed through dashboards, work flow management systems, and the like.
Finally, The most important and yet often hardest to design is a conduit or the “glue” that ties all these blocks together to create an efficient and effective system for advertising.
Now, each of the abstractions described above expose several data science problems that are explored in the next section.
Organizational abstractions
For the sake of completeness, in a rather terse way, the general steps involved in an organization to setup the strategy for marketing is reproduced from [2], below.
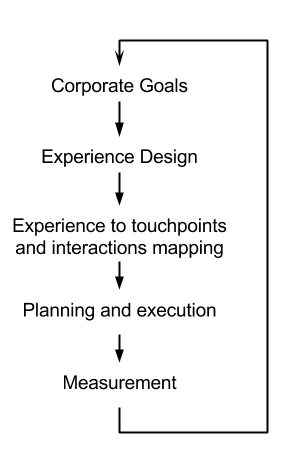
For a detailed treatment of how this can be achieved whilst avoiding common pitfalls like the creation of silos within teams, creating transformative changes in the organization, re-structuring to deal with the “new” interconnected nature of advertising without affecting team morale, etc. Please refer [2].
Data Science and Analytics Problems in Computational Advertising
In this section, relevant topics in computational advertising that involve the use of scientific and engineering tools are described. The discussion is further categorized based on the methodology required – quantitative and/or qualitative, and based on technological abstractions and stakeholders described in the previous section.
It has to be noted that although for the sake of clarity, the problems have been bucketed under certain headings, they are often interconnected and have an impact on other stakeholders or technology blocks.
-
Customer Segmentation and Audience Creation
Creating customer segments involves defining rules that can be applied to available data sources to extract “clusters”. This can be done in three ways:
- Qualitative data collection and analysis techniques such as structured and unstructured interviews, focus groups, and surveys [7, 8, 9].
- Based on processes that capture various important business metrics like lifetime-value (LTV) of a customer, cost of acquisition, data availability, and addressability of the segment [5] or business specific data [4].
- Using clustering methods in machine learning like K-means, Latent Dirchlet allocation, PLSA, and the like. [6]. In such cases, various cluster purity measures can be used to measure the robustness of segments [10].
In all cases, segmentation is usually followed by identifying representative samples of each segment that can be described using features or words that are easy to understand: it could be the most representative rule, if decision trees are used, value of numeric variable used to generate the cluster, etc. These are known as personas. The segments may also be summarized with descriptive statistics (such as stating that 75% of the segment users used an iPhone everyday), into what are called profiles. These profiles and personas aid the creative process: to generate content and design experience for a customer at various touch points. It is also important to point out that segmentation often helps target ads to prospects at the top of the marketing funnel. A common pitfall is to over-rely on segments for targeting [2]. They should always be combined with contextual information. Additionally, the concept of assigning a data point to a segment need not be mutually exclusive; soft-assignments through propensity models may also be explored.
-
Channel experience design
Channel experience design is a creative activity and involves the design of a process document for capturing a creative brief. This may involve discussing with the stakeholders within an agency or the advertiser to identify:
- What the customer should feel, need, or do.
- The competitive advantage or the “selling edge” of the advertiser.
- Insights on the customer segment and their perspectives.
- Best ways to solicit customer response.
All of these steps require a good understanding of the stakeholders involved, the right communication skills and knowledge of the best practices of various Qualitative research techniques, so that the process can be standardized as much as possible in the interest of efficiency (e.g. to allow for legal approvals of minor variants) and effectiveness (e.g. quality of segments wrt. conversion).
Additionally, one has to abstract insights gained about the customer into a “decision diagram” that captures the rationale behind why a user would “convert”. As an example from [2], this could be through the identification of the following chain of reactions: Brand Attributes (e.g. Offers, Convenient location) –> Brand Benefits (e.g. Good customer experience, Value for money) –> Personal Emotions (e.g. Feel valued, Confident) –> Personal Values (e.g. Pride, Peace of Mind).
The resulting brief should visualize and capture all the aforementioned content in a short 1-2 page document; it should be tested, through campaigns, focus groups, or the like. Preparing such a brief is an iterative process. In order to test various strategies that are outcomes of the brief, techniques like A/B [11], Multi-arm bandit [12], and the Taguchi method [13] can be used and are introduced again, as a part of the Content Optimization problem later.
-
Budget Allocation
The budget allocation problem deals with the amount and type of budget that should be allocated. It could happen along the following dimensions:
- Digital vs. Traditional advertising
- Publishers and ad-networks (e.g. Facebook vs. Google vs. Twitter) in computational advertising,
- Type of delivery, i.e. as a part of search results (search advertising), social media feeds (social media advertising), or as display banners (display advertising).
- Nature of contracts with the publisher, viz. Real-time Bidding, Programmatic Guaranteed or API-driven buying, or Guaranteed Media Buying (through what are known as Over-the-counter or OTC contracts). This is relevant as residual ad slots are often sold over RTB by a lot of publishers while allocating the most valuable slots through guaranteed contracts [2].
- Various parts of the conversion funnel: Prospecting vs. Remarketing vs. Cross-selling; Segment based targeting vs. Personalization lower down the funnel. This decision is complex and has to be based on addressability of market segments through these various types of advertising media, costs, and conversion rates in addition to organizational factors such as risk appetite, comfort with technology, and the like.
-
Contract negotiation and Stakeholder’s Optimization
Contracts are usually negotiated in two ways:
- Forward contracts that are usually used with OTC contracts in which the advertiser purchases impressions in advance for some future time period. This is also called Guaranteed media buying. Alternatively they are also used transparent markets to purchase guaranteed ad slots, but through decisioning mechanisms that are controlled by the publisher (such as Yahoo! Guaranteed inventory or Facebook Inventory through an API developer)
- On the spot contracts that are used in markets that have transparent pricing through auctioning methods where the advertisements are bought immediately.
In the case of forward contracts, using various mathematical optimization techniques are relevant from the perspectives of all stakeholders, namely, the ad exchanges, publishers, and advertisers. Each of them are discussed below:
-
Ad Networks
In the case of Ad networks, the objective of “optimization” would be to improve their revenues during auctioning. In this context, it is worthwhile to consider various auctioning models in vogue and that have phased out:
- 1st price negotiation and 1st price reservation are simple auctioning mechanisms that are used for manual selection of the most preferred contract or for implementing first-come-first-serve basis; they are relevant for OTC contracts).
- 2nd Price auctions are the most common auctions used in the context of the Real time bidding (RTB) industry. At a high level, they work in two steps; first, they combine quality and relevance of the creative or the advertiser with the bid price to come up with a score; next, they use the price of the 2nd highest bid to determine the price the winner of the bid pays. A natural advantage of this method is that the quality and relevance can be factored into the bidding process (including possibly positional bias) and it also supports true RTB and pre-set bids (PSB). The generalized 2nd price auction [14] is the most adopted model nowadays in Ad Exchanges. It is briefly defined below due to its importance. Let’s say there are
 ordered slots
ordered slots 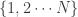 and
and  bidders. Let the probability of a slot in position
bidders. Let the probability of a slot in position  being clicked be given by
being clicked be given by  with
with 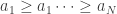 . Let the bids of the K bidders and their “quality” scores be given by
. Let the bids of the K bidders and their “quality” scores be given by 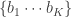 and
and 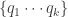 . Then, the payment to the search engine for position is given by
. Then, the payment to the search engine for position is given by  A detailed discussion on its evolution in [14].
A detailed discussion on its evolution in [14].
-
Publishers and SSPs
In the case of publishers or SSPs, the objective is to improve revenue whilst controlling relevance of advertisements. The discussion of problems can further be dissected based on the type of advertising: i.e. whether it is search, display, or social media advertising.
In search advertising, relevance optimization amounts to determining (a) how many ads to show with a search result, (b) which ads to show (after bidding), and (c) where to show the ads. For (a), in literature, there are several studies involving eye tracking on pages [15, 16, 17, 18]. For (b) and (c), the problem is many-fold. Firstly, should an ad be displayed at all for a given search query or page? This is called the swing problem [19]. Secondly, how can the relevance score be computed? This has been done using a variety of techniques; with vector-space representation [20, 21] being used for extracting features and a variety of algorithms such as decision trees [25], SVMs [24], logistic regression [22], Bayesian Networks [23], and the like, for carrying out inference. These are tabulated well in [2]. Thirdly, relevance and revenue are sometimes at loggerheads. There is a need to achieve a certain number of impressions to generate revenue, but a lack of relevance can affect user experience and over a period of time, drive revenue down. So the aforementioned relevance improvement methods may have to be coupled with ways of also having sufficient addressability: This could be in the form of identifying relevant ads for uncommon queries (belonging to the long tail) using methods like query expansion using WordNet or by building models that optimize for total revenue whilst respecting daily budgets of bidders. This forms the basis for the AdWords problem described in [26]. In general, publishers in search advertising also have the advantage of exploiting the “semantic information” readily available in textual data.
In the case of display advertising on mobile phones, videos, and display, an important problem is to again determine the best location for advertisements. In the case of videos, this problem is particularly complex; in literature, it has been addressed in a variety of ways such as identifying points of discontinuity, determining locations that are least obstructive, etc. The aforementioned swing problem, optimizing revenue and relevance are valid for these types of advertising as well.
Social media advertising on the other hand provides a much more unique opportunity; while the swing, revenue and relevance problems are still relevant, the tend to transfer the targeting control to the advertiser or the buy-side. Forward contracts are still used, but the relevance parameters are usually preset, with the bid-optimization being managed by the publisher. The traditional relevance problem has to be re-defined in terms of how, where, and how frequently sponsored content may be interspersed with “feeds” to provide optimal revenue whilst not annoying a user: this may be done indirectly through CTR experiments and the like, or using various experiment design methodologies like multi-arm bandit.
Lastly, the problem of revenue optimization is also closely tied to the issue of honoring contract requirements such as providing a certain number of impressions within a given time period or a certain number of actions, in the case of display advertising. This topic has also been investigated in the literature [30].
-
Advertisers and DSPs
Advertisers want their impressions delivered to the right audience at the lowest cost. DSPs may still want to improve their revenues (which might be a percentage of the ad spend), but they predominantly represent the advertiser’s interests. The following problems are relevant to them:
Optimizing targeting: This involves choosing the right criteria to deploy advertisements. They can be of the following kinds:
- Behavioral: phone usage, web browsing history
- Attitudinal: emotions, preferences, needs
- Motivational: why behind the buy, underlying motivations
- Demographic: pertaining to age, location, affluence
A special case for search advertising would be to map behavioral and attitudinal information to keywords and therefore, optimize keyword selection. As an example, in literature, linear programming, keyword bid statistics, and multi-arm bandit algorithms have been used [27, 28]. A related problem is determining target size [29]. The target size is important for an advertiser as it helps set an expectation on the budget that can be burnt in a given time for a given target criteria.
The target optimization problem is further complicated in practice, by the need to burn money in a meaningful manner during the entire duration of a campaign. Various methods have been proposed to place good quality bids in literature [31, 33, 36, 37].
Conceptually, the various dimensions that will have to be optimized jointly are:
- Criteria: keywords and/or behavioral, attitudinal, motivational, and demographic variables for improving the CTR, CPM, or any other metric that’s relevant.
- Burn-rate: requiring uniformity and minimization of the risk of pre-mature campaign termination.
- Burn-rate fluctuation: burn-rate to be relatively smooth and at the same time capture the traffic patterns; uniform burn rate is considered disadvantages because it disregards information about the time of the day when high quality and quantity impressions are possible.
- Re-targeting frequency: the number of times a single identity is shown an ad
- Creative choice: the possible choices could include different creative sizes(e.g. interstitial vs. banner), content, and types (e.g. video vs. banner vs. interactive) .
The objective is to eventually develop a bidding function that positively impacts the KPI of the organization. This has also been discussed in literature [32].
All in all, target optimization enables us to chose the right auctions to bid on; there are two sub problems in bidding: making a decision as to whether to bid or not, and if the decision is to bid, setting the bid price. These have to be solved as a part of the previous problem.
Although unrelated to mathematical optimization, it is important to mention here that adding new sources of information, triangulating variables (such as geo IP mappings), and exploring new dimensions are equally important to improving targeting quality. This could be through the use of data management platforms that act as a syndication of data sources. Also, it is important to understand three kinds of data commonly referred to in advertising:
- First-party data: is the data owned by the stakeholder that we’re talking about. e.g. CRM database of an advertiser is his first-party data.
- Second-party data: is the first-party data of someone else. For example, buying Facebook’s data would amount to purchasing second-party data.
- Third-party data: is someone else’s data sold by an intermediary.
For a description of how a DMP works, the reader is pointed to [34].
-
Content Optimization
Content optimization happens at two places: Firstly, the creative content has to be optimized through an iterative process. This has to be documented in the brief. Secondly and most importantly, the content in the channels of the advertiser has to be worked upon to “create” the experience that has been designed for the prospect. This amounts to building “personalization”. Personalization is defined as “the enablement of dynamic insertion, customization, or suggestion of content in any format that is relevant to the individual user, based on the individual user’s implicit behavior and preferences, and explicit customer provided information”[2].
At every touchpoint on the channel, the user defines a clear a topic: such as product, services, loyalty, up-sell, cross-sell, or general questions. It is therefore the objective of “personalization” to address such needs of the user in context, with specificity. Concretely, for instance, the choice of offer may be different for a returning customer and a prospect who is at the “consideration” part of the marketing funnel. The choice of offers to be shown, its positioning on the website, and surrounding content will have to be optimized using various techniques in experiment design such as A/B testing, multi-arm bandit, the Taguchi method, and the like. This is a an iterative process and involves analyzing web analytics logs and event streams to identify drop-offs for various strategies (chosen through experiments), time spent on pages, etc. in order to further improve conversion rates.
-
Measurement and Analysis
The first and the foremost problem of an advertising solution is being able to measure the performance of the various technological abstractions that was described in the previous section. For example, what is the accuracy of identity matching? what are the false positive and false negative rates? What is the accuracy of the data provided by the DMP? How well is a targeting criteria performing? What is the LTV of a customer? What is the value of an impression? How good is the outcome of an advertising campaign? Why are prospects dropping off of a conversion funnel? Why is there a churn?
While the list of questions given above are not exhaustive, they are indicative of the absolute necessity of defining metrics at various stages and measuring them. Such measurements may also be necessary in a lot of the optimization and other data science problems discussed above. Some of the abstractions may not be “measurable” (e.g. customer segments), in which case, they may have to be studied in depth as to whether such abstractions make sense or if their quality has to be measured indirectly. All in all, a comprehensive plan for a measurement rig is absolutely essential.
In addition to making measurements, it is also essential to make measurements comparable where it make sense. The pricing for an impression, for example, is given through metrics like Cost-per-mille (CPM), Cost-per-Click (CPC), Cost-per-acquisition (CPA), and so on. In the case of bids, the ad exhange uses what is known as a dynamic CPM with the CPM varying between bids. In order to get the bid value to the same currency, a DSP or an advertiser may chose to normalize it eCPM (or effective CPM that normalizes CPM by the expected number of impressions).
Apart from these fundamental challenges with making the entire solution measurable at various stages, the following measurement-related problems require data-driven solutions.
-
Fraud detection
Internet advertising fraud is a major loss of revenue for advertisers. Recent reports suggest that ad frauds in 2016 amount to about 7.6 Billion USD! [38] Also, some sources suggest that up to 60% of ad traffic constitutes fraud [39]. Fraud happens because of fake clicks on advertisements that are a irrecoverable cost to the advertiser.
Various methods to detect or prevent fraud has been presented in literature by different stake holders such as advertisers and ad networks [40, 41, 42]; nevertheless, it has been broadly acknowledged, both in media and research that this is a pervasive and tough problem to solve.
-
Attribution
Attribution refers to the identification of the cause for a conversion or an interaction on a channel. Attribution is important as it enables us to understand and optimize user experience and therefore lead to more conversions. It also helps us allocate the right advertising budget to various portions of the conversion funnel. The simplest strategy for attribution is known as “last-touch” attribution that assigns the complete cause for a conversion to be the most recent interaction. This leads to erroneous results when the marketing solution involves, say, remarketing messages and various personalization steps, that eventually lead to a conversion. As an alternative, more complicated attribution models have been proposed in literature that assign attribution to multiple sources using techniques from game theory, time-series models, aggregations, and machine learning and are generally called “fractional attribution” or “multi-touch attribution” models [43, 44, 45, 46].
-
Cross-device identification
With the large always-on-mobile population as well as the pervasiveness of the websites and social media, and the possible existence of rich offline data collected by advertisers, it is becomes imperative that one is able to triangulate all of these data sources to identify individual users. However, this is a challenge due to the following reasons:
- The creation of “Walled Gardens” by large publishers that limit exposure of user identities to the advertiser in the absence of an interaction.
- The use of multiple devices by a single user
- The use of identities that are unique to a device (e.g. IDFA or Android ID) and the lack of cookie management in smartphones and tablets
- The possibility of clearing a cookie by the user, and
- Popularity of browser addons like AdBlocker, Ghostery, etc.
- Lack of sufficient identity information or ambiguity in the case of offline to online data matching.
As a result, identifying a user across devices or websites, where not directly possible, is sometimes attempted using probabilistic methods. Such methods rely on similarity of or correlation between variables to match users. The accuracy of such systems have not been extensively studied (or made available as public literature) although a robust system can potentially open up great possibilities.
-
User Perceptions of Advertising
One of the most important questions that an advertiser has to answer for himself is about the perception of advertisements by a user along several dimensions: whether it is relevant or annoying, whether it is visible or obscurely placed, and whether the targeting and data collection mechanisms used by the advertiser (and possibly the publisher) are perceived to be privacy-sensitive.
Here, the importance of privacy needs to be underscored and qualitative studies in literature have also explored this [47]. The control of privacy may also have to be given to the user (as evidenced by recent changes to Facebook settings), the use of PII avoided, privacy policy written in simple language (as have many companies including Facebook and Google have) etc. This is an ongoing and active research area, given its subjective nature and continually changing user attitudes. Understanding them along with government regulations are very essential for both, ensuring a compliant and acceptable solution and to influence policy making as a stakeholder.
Lastly, with the advent and popularity of various plugins and add-ons on phones and browsers that disable advertisements (like Ghostery, AdBlock Plus, etc.), it is also imperative to understand user attitudes to advertising in various contexts through qualitative and quantitative research methods.
This brings us to the end of the rather longish article. Do share feedback and comments!
References
- [1] Shaui Yuan, Ahmad Zainal Abidin, Marc Sloan, Jun Wang. Internet Advertising: An interplay among Advertisers, Online Publishers, Ad Exchanges, and Web Users. Preprint. Information Processing and Managment. 2012.
- [2] Craig Dempster, John Lee. The raise of the Platform Marketer: Preformance Marketing with Google, Facebook, and Twitter plus High-Growth Digital Advertising Platforms. Wiley and Sons. 2015.
- [3] Luma Partners. LumaSCAPE. http://www.lumapartners.com/lumascapes/display-ad-tech-lumascape/. Accessed 21 Jun 2016.
- [4] Thorsten Teichert, Edlira Shehu, Iwan von Wartburg. Customer segmentation revisited: The case of the airline industry. Transporation Research. pp. 227-242. 2008.
- [5] Su-Yeon Kim, Tae-Soo Jung, Eui-Ho Suh, Hyun-Seok Hwang. Customer segmentation and strategy development based on customer lifetime value: A case study. Vol. 31. pp. 101-107. 2006.
- [6] Wu X, Yan J, Liu N, Yan S, Chen Y, Chen Z. Probabilistic latent semantic
user segmentation for behavioral targeted advertising. In: Proceedings of the
3rd International Workshop on Data Mining and Audience Intelligence for
Advertising. 2009. p. 10–7.
- [7] Jenny Kitzinger. Introducing Focus Groups. BMJ. Vol. 311. pp. 299-302. 1995.
- [8] Annabel Bhamani Kajornboon. Using interviews as research instruments. Technical Report. Chulalongkorn University. http://www.culi.chula.ac.th/Research/e-Journal/bod/Annabel.pdf. Accessed June 20, 2016.
- [9] Rosalind Edwards, Janet Holland. What is qualitative interviewing? “What is” Research Method Series. Bloomsbury. 2013.
- [10] Sabine Schulte im Walde. Chapter 4: Clustering Algorithms and Evaluation. Experiments on the Automatic Induction of German Semantic Verb Classes. Institut für Maschinelle Sprachverarbeitung, Universität Stuttgart, June 2003.
- [11] Wikipedia. A/B Testing. https://en.wikipedia.org/wiki/A/B_testing . Retrieved June 20, 2016.
- [12] Joann es Vermorel, Mehryar Mohri. Multi-armed Bandit Algorithms and Empirical Evaluation. ECML. pp. 437-448. 2005.
- [13] Roy R. A primer on taguchi method. Society of Manufacturing Engineers, 1990.
- [14] G Aggarwal, S Muthukrishnan. Theory of sponsored search auctions. In: Foun-
dations of Computer Science, 2008. FOCS’08. IEEE 49th Annual IEEE Sym-
posium on. IEEE; 2008. p. 7–.
- [15] Granka L, Joachims T, Gay G. Eye-tracking analysis of user behavior in www
search. In: Proceedings of the 27th ACM SIGIR Conference on Information
Retrieval. ACM; 2004. p. 478–9.
- [16] Granka L, Joachims T, Gay G. Eye-tracking analysis of user behavior in www
search. In: Proceedings of the 27th ACM SIGIR Conference on Information
Retrieval. ACM; 2004. p. 478–9.
- [17] Enquiro . Barriers on a search results page. 2008.
- [18] Gord Hotchkiss SA, Edwards G. Google eye tracking report. http://pages.
enquiro.com/whitepaper-enquiro-eye-tracking-report-I-google.
html (last visited 13/12/2011); 2005.
- [19] Broder A, Ciaramita M, Fontoura M, Gabrilovich E, Josifovski V, Metzler D,
Murdock V, Plachouras V. To swing or not to swing: learning when (not) to
advertise. In: Proceeding of the 17th ACM Conference on Information and
knowledge Management, CIKM. ACM; 2008a. p. 1003–12.
- [20] Broder A, Ciccolo P, Fontoura M, Gabrilovich E, Josifovski V, Riedel L.
Search advertising using web relevance feedback. In: Proceedings of the 17th
ACM Conference on Information and Knowledge Management, CIKM. ACM;
2008b. p. 1013–22.
- [21] Broder A, Ciccolo P, Gabrilovich E, Josifovski V, Metzler D, Riedel L, Yuan J.
Online expansion of rare queries for sponsored search. In: Proceedings of the
18th International Conference on World Wide Web. 2009. p. 511–20.
- [22] Hillard D, Schroedl S, Manavoglu E, Raghavan H, Leggetter C. Improving
ad relevance in sponsored search. In: Proceedings of the 3rd International
Conference on Web Search and Data Mining. 2010. p. 361–70.
- [23] Radlinski F, Broder A, Ciccolo P, Gabrilovich E, Josifovski V, Riedel L. Op-
timizing relevance and revenue in ad search: a query substitution approach.
In: Proceedings of the 31st ACM SIGIR on Information Retrieval. 2008. p.
403–10.
- [24] Richardson M, Dominowska E, Ragno R. Predicting clicks: estimating the
click-through rate for new ads. In: Proceedings of the 16th International
Conference on World Wide Web. 2007. p. 521–30.
- [25] Neto BR, Cristo M, Golgher PB, de Moura ES. Impedance coupling in content-
targeted advertising. In: Proceedings of the 28th ACM SIGIR on Information
Retrieval. 2005. p. 496–503.
- [26] Mehta A, Saberi A, Vazirani UV, Vazirani VV. Adwords and generalized on-
line matching. In: Proceedings of the 46th Annual IEEE Symposium on
Foundations of Computer Science. 2005. p. 264–73.
- [27] Even-Dar E, Mirrokni VS, Muthukrishnan S, Mansour Y, Nadav U. Bid opti-
mization for broad match ad auctions. In: Proceedings of the 18th Interna-
tional Conference on World Wide Web. 2009. p. 231–40.
- [28] Rusmevichientong P, Williamson DP. An adaptive algorithm for selecting prof-
itable keywords for search-based advertising services. In: Proceedings of the
7th ACM Conference on Electronic Commerce. 2006. p. 260–9.
[29] S. Muthukrishnan. Internet Ad Auctions: Insights and Directions. ICALP. 2008. pp. 14-23
- [30] Korula, Nitish, Vahab Mirrokni, and Hamid Nazerzadeh. “Optimizing display advertising markets: Challenges and directions.” Available at SSRN 2623163 (2015).
- [31] Kuang-Chih Lee,Ali Jalali, Ali Dasdan, Real Time Bid Optimization with Smooth Budget Delivery in Online Advertising. ADKDD 2013.
- [32] Weinan Zhang, Shuai Yuan, Jun Wang. Optimal Real-Time Bidding for Display Advertising. KDD 2014.
- [33] Shuai Yuan, Jun Wang, Xiaoxue Zhao. Real-time Bidding for Online Advertising: Measurement and Analysis. ADKDD 2013.
- [34] Hazem Elmeleegy, Yinan Li, Yan Qi, Peter Wilmot, Mingxi Wu, Santanu Kolay, Ali Dasdan. Overview of Turn Data Management Platform for Digital Advertising. Proceedings of the VLDB Endowment, Vol. 6, No. 11. 2013.
- [35] IAB. OpenRTB Specification. http://www.iab.com/wp-content/uploads/2015/05/OpenRTB_API_Specification_Version_2_3_1.pdf . Accessed June 22, 2016.
- [36] Shahriar Shariat, Burkay Orten, Ali Dasdan. Online Model Evaluation in a Large-Scale Computational Advertising Platform. arXiv:1508.07678v1 CS:AI. 2015.
- [37] Kuang-chih Lee, Burkay Orten, Ali Dasdan, Wentong Li. Estimating Conversion Rate in Display Advertising from Past Performance Data. KDD 2012.
- [38] George Slefo. Ad Fraud Will Cost $7.2 Billion in 2016, ANA Says, Up Nearly $1 Billion. http://www.adageindia.in/digital/ad-fraud-will-cost-7-2-billion-in-2016-ana-says-up-nearly-1-billion/articleshow/50647542.cms . Accessed June 22, 2016.
- [39] Mathew Ingram. There’s a ticking time bomb inside the online advertising market.
http://fortune.com/2015/07/01/online-advertising-fraud/ . Accessed June 22, 2016.
- [40] Linfeng Zhang and Yong Guan. Detecting Click Fraud in Pay-Per-Click Streams of Online Advertising Networks. The 28th International Conference on Distributed Computing Systems. 2008.
- [41] Hamed Haddadi. Fighting Online Click-Fraud Using Bluff Ads. arXiv:1002.2353v1 CS: CR. 2010.
- [42] Neil Daswani, Chris Mysen, Vinay Rao, Stephen Weis,. Online Advertising Fraud. Book Chapter from Crimeware. Symantic Press. 2008.
- [43] Ron Berman. Beyond the Last Touch: Attribution in Online Advertising. Technical Report. 2015.
- [44] Pavel Kireyev, Koen Pauwels, Sunil Gupta. Do display ads influence search? Attribution and dynamics in online advertising. International Journal of Research in Marketing. 2015.
- [45] Sahin Cem Geyik, Abhishek Saxena, Ali Dasdan. Multi-Touch Attribution Based Budget Allocation in Online Advertising. ADKDD 2014.
- [46] Xuhui Shao,Lexin Li. Data-driven Multi-touch Attribution Models. KDD 2011.
- [47]Predrag Klasnja, Sunny Consolvo, Tanzeem Choudhury, Richard Beckwith, and Jeffrey Hightower. 2009. Exploring Privacy Concerns about Personal Sensing. In Proceedings of the 7th International Conference on Pervasive Computing (Pervasive ’09), Hideyuki Tokuda, Michael Beigl, Adrian Friday, A. J. Brush, and Yoshito Tobe (Eds.). Springer-Verlag, Berlin, Heidelberg, 176-183.